A one-stop solution for
AI inference and fine-tuning integrated machines for government and enterprise access
一、Deepseek inference fine-tuning all-in-one machine has become the preferred choice for enterprise AI application deployment
Under DeepSeek’s accelerated deep integration into the industry, AI has gradually become a necessity for enterprises. Due to the need for data privacy in enterprises, after the popularity of ChatGPT, large model all-in-one machines were pushed to the government and enterprise markets by IT vendors to solve problems such as insufficient training computing power and inability to prevent data leakage outside the domain. The excellent performance of DeepSeek has led to a surge in demand for government and enterprise companies to introduce DeepSeek, and there is an urgent need for stable and highly available solutions. Purchasing all-in-one machines to use DeepSeek has naturally become the first choice.
The use of all-in-one machines for private deployment of large models has the following advantages:
High stability: Compared to public servers that are easily impacted by huge traffic, private computing power is clearly more secure and has better stability.
Simplified deployment: Traditional large-scale model deployment requires processes such as hardware debugging, framework adaptation, and operator optimization. The pre installed large-scale model and supporting toolchain on all-in-one machines greatly reduce the threshold for enterprise use, truly realizing out of the box use, shortening project deployment cycles, and helping enterprises quickly start AI application practices.
Model customization: Enterprises can continuously train models through private data or install internal knowledge bases to transform generic large models into “experts” in vertical fields, adapting to specific business scenarios of the enterprise.
Economic effect: In the short term, using large models through cloud services does not require a one-time hardware investment, but in the long term, using public cloud APIs for token based payment incurs higher costs. Deploying through one machine privatization can help reduce overall costs and better control budgets.
Data Security: For users with a large amount of sensitive data, deploying localized large models can be used without networking, ensuring that data is processed locally, avoiding sensitive information leakage, and meeting the security and privacy requirements of data sensitive industries such as finance, energy, government, and healthcare.
二、 DeepSeek inference fine-tuning one-stop privatization all-in-one deployment solution
The DeepSeek inference fine-tuning one-stop private all-in-one deployment solution launched by Hengbao Intelligent Network provides a more flexible and efficient mode for enterprises and developers to access DeepSeek, including the following aspects:
- High performance DS all-in-one machine: out of the box, enabling efficient deployment and inference of DeepSeek.
- DeepSeek big model localization deployment: Deepseek v3 can be deployed on demand according to business needs, deepseek-R1, And Deepseek-R1-Distill version.
- The complete LLMOps big model application development kit: helps enterprises build proprietary knowledge bases, enhance generation through RAG retrieval, reduce the illusion of big models, and further improve the quality of answering questions. Simultaneously supporting AI agents/workflows, supporting automation and intelligence of business processes both inside and outside the enterprise
- Customized development of industry applications: Enterprise level customized services to meet the needs of different scenarios and assist in the implementation of AI applications for various industries

三、DeepSeek inference fine-tuning all-in-one machine
The DeepSeek inference fine-tuning all-in-one machine has been adapted to the deep optimized DeepSeek large model, supporting distillation models of 1.5B, 7B, 8B, 14B, 32B, 70B, 671B and native large models. With the hardware vertical optimization of the Hengbao Zhiwang GPU server and the deep adaptation of the DeepSeek model, the inference performance of the large model can be greatly improved.
The hardware configuration of a single machine can provide up to 192GB of video memory, divided into two versions: basic version and flagship version, supporting multi machine parallel inference and meeting high concurrency business requirements. Full process development support covers AI development services from data governance, model fine-tuning, inference services to operation and maintenance management; Provide out of the box AI development tools and services to lower technical barriers and shorten deployment cycles. Data security and privacy protection are achieved through private deployment, where data and applications are deployed on the internal infrastructure of the enterprise, enabling localized storage and management of data, ensuring the autonomy, controllability, security, and compliance of enterprise data.
Deploy the 1.5B-70B model with FP16 model accuracy, and recommend using one unit; Deploy 671B full health version, using INT8 and FP16 model accuracy, recommended to use 4-8 units.
| Basic Edition | flagship version | |
| Key configurations | • 1 Intel/AMD CPU | • 2 Intel Xeon CPU |
| • 8*32GB R-ECC DDR4 3200MHz | • 16*32GB R-ECC DDR4 3200MHz | |
| • 2*480G SATA SSD Hard disk, 2*3.84T NVME | • 2*480G SATA SSD Hard disk, 2*3.84T NVME | |
| • 4*GeForce RTX4090 24G | • 8*GeForce RTX4090 24G | |
| • 0*GPU Exchange board | • 1*GPU Exchange board | |
| • 1*Dual port 10 Gigabit Ethernet card,1*Onboard gigabit Ethernet port | • 1*Dual port 10 Gigabit Ethernet card,1*Onboard gigabit Ethernet port | |
| • 2700W(1+1)Redundant power supply | • 2000W(3+1)Road redundant power supply | |
| • Form: desktop tower or2U | • Form: 4U server | |
| model parameter | Default Run DeepSeek-R1-Distill-Qwen-32B | Default Run DeepSeek-R1-Distill-Llama-70B |
| • Support operation1.5B,7B,8B,14B, | • Support operation 1.5B,7B,8B,14B,32B版本 | |
| • Support operation70BQuantitative version | • Support operation670BQuantitative version | |
| Built in software | operating system:Ubuntu 22.04 | |
| Model platform:vLLM、SGLang、Ollama,Default use of vLLM platform | ||
| Other: RAG platform builds knowledge base, industry intelligent agent assistant, ChatBot tool assistant | ||
| technical service | Support remote technical services and accept customized services for secondary development | |
四、 The overall architecture of LLMOps large model application development kit
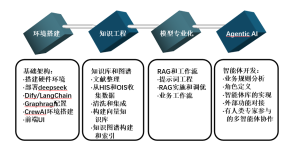
The landing of DeepSeek in government and enterprise requires not only a few all-in-one machines, but also a series of capabilities such as computing power management and scheduling platform, AI development tools, and operation and maintenance services to work together. It is also necessary to integrate proprietary data, industry knowledge, etc. for fine-tuning, building, and managing local knowledge bases. At this time, tools are needed to truly deliver DeepSeek and other large models to the business scenarios of government and enterprise customers.
Hengbao Zhiwang provides a one-stop application development kit for LLMOps large models, with a built-in full stack AI application capability tool library. It provides a toolchain covering the entire process of data engineering, knowledge fine-tuning, deployment, optimization, etc., reducing the tedious adaptation work of government and enterprises in model docking and quickly using DeepSeek. Including the following:
Professional knowledge enhancement: RAG toolset, knowledge graph toolset, professional knowledge base, knowledge graph and prompt words
AGI environment: workflow toolkit, agent development framework, and intelligent agent toolkit
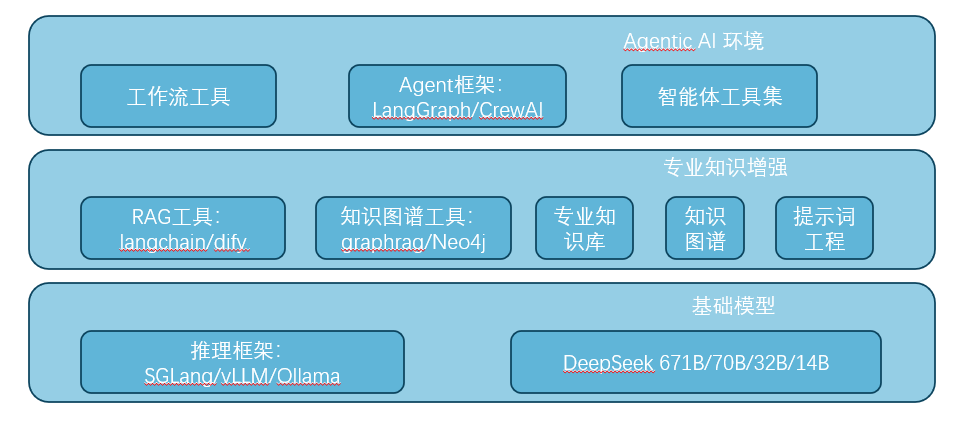
At the same time, the LLMOps application development kit can adapt to different basic large models, such as DeepSeek which is excellent at present, but the evolution speed of large models is also very fast. In order to make AI all-in-one machines have evolutionability and reduce the comprehensive use cost of government and enterprise AI, it is also important to support diversified large models. Hengbao Intelligent Network LLMOps are pre installed to adapt to multiple mainstream models. As it fully adapts to series models such as DeepSeek V3 and DeepSeek R1, and is also compatible with mainstream open-source models such as Qwen2.5 and LLama3.2, it flexibly supports the diversified business needs of government and enterprises.
LLMOps Large Model Application Development Kit Presentation:
五、Delivering High-Efficiency Deployment
By adopting the DeepSeek inference fine-tuning one-stop private deployment solution from Jaguar Network, government and enterprise customers no longer need to invest significant time and effort in technical preparation. With just one click, they can deploy and schedule the system. This transforms DeepSeek’s complex deployment process into a ‘turnkey project,’ reducing the deployment cycle for governments and enterprises and lowering time costs. It quickly enables these organizations to adapt to scenarios such as intelligent customer service and dialogue, text analysis, industrial quality inspection, and medical image recognition, allowing companies to avoid starting from scratch and significantly shortening the AI application launch period.
High-efficiency delivery allows government and enterprise business innovation to stay ahead of the curve, making it highly attractive to businesses across various industries vying for DeepSeek’s hotspots. It makes AI immediately usable and valuable upon use, truly providing an efficient, reliable, and cost-effective path for intelligent upgrades for governments and enterprises.
六、Value Advantages of the Constant Leopard Smart Network Training and Inference Integrated Machine Solution:
1) High Cost-effectiveness DeepSeek Integrated Machine
Available in basic and flagship versions, it supports parallel inference across multiple machines, allowing for smooth scaling based on business needs and reducing initial investment.
2) Comprehensive One-stop LLMOps Services for Various Scenarios
Offers a full suite of LLMOps large model application development kits (such as RAG, Agents, vectorization, model management), truly integrating DeepSeek and other large models into government and enterprise business scenarios.
3) Multi-layer Protection Mechanisms Ensuring DeepSeek’s Safety and Stability
A security system with multi-layer protection mechanisms covers aspects like input filtering, output review, and encrypted data transmission, ensuring the safety and privacy of generated content. It also sets different access permissions for local deployment of large models and automatically clears cache after inference output.
4) Expert-Level Services
A professional, comprehensive, and reliable team providing rapid hour-level response services to customers.